DoubletFinder
DoubletFinder is a transcription-based doublet detection software that uses simulated doublets to find droplets that has a high proportion of neighbors that are doublets. We have provided a wrapper script that takes common arguments for DoubletFinder and we also provide an example script that you can run manually in R if you prefer.
Data
This is the data that you will need to have preparede to run DoubletFinder:
Required
A QC-filtered and normalized seurat object saved as an
rdsobject ($SEURAT_RDS)For example, using the Seurat Vignette
If you run DoubletFinder manually, you can use any data format of interest and read in with a method that works for your data.
Output directory (
$DOUBLETFINDER_OUTDIR)Expected number of doublets (
$DOUBLETS)This can be calculated based on the number of droplets captured using our Doublet Estimation Calculator
Run DoubletFinder
⏱️ Expected Resource Usage
~1h using a total of 15Gb memory when using 2 thread for the full Test Dataset which contains ~20,982 droplets of 13 multiplexed donors,
You can either run DoubletFinder with the wrapper script we have provided or you can run it manually if you would prefer to alter more parameters.
DOUBLETFINDER_OUTDIR=/path/to/output/DoubletFinder
SEURAT_RDS=/path/to/TestData_Seurat.rds
DOUBLETS=3200
singularity exec Demuxafy.sif DoubletFinder.R -o $DOUBLETFINDER_OUTDIR -s $SEURAT_RDS -c TRUE -d $DOUBLETS
HELP! It says my file/directory doesn’t exist!
If you receive an error indicating that a file or directory doesn’t exist but you are sure that it does, this is likely an issue arising from Singularity. This is easy to fix. The issue and solution are explained in detail in the Notes About Singularity Images
You can provide many other parameters as well which can be seen from running a help request:
singularity exec Demuxafy.sif DoubletFinder.R -h
usage: DoubletFinder.R [-h] -o OUT -s SEURAT_OBJECT -c SCT -d DOUBLET_NUMBER [-p PCS] [-n PN]
optional arguments:
-h, --help show this help message and exit
-o OUT, --out OUT The output directory where results will be saved
-s SEURAT_OBJECT, --seurat_object SEURAT_OBJECT
A QC, normalized seurat object with classifications/clusters as Idents() saved as an rds object.
-c SCT, --sct SCT Whether sctransform was used for normalization.
-d DOUBLET_NUMBER, --doublet_number DOUBLET_NUMBER
Number of expected doublets based on droplets captured.
-p PCS, --PCs PCS Number of PCs to use for 'doubletFinder_v3' function.
-n PN, --pN PN Number of doublets to simulate as a proportion of the pool size.
First, you will have to start R. We have built R and all the required software to run DoubletFinder into the singularity image so you can run it directly from the image.
singularity exec Demuxafy.sif R
That will open R in your terminal. Next, you can load all the libraries and run DoubletFinder.
.libPaths("/usr/local/lib/R/site-library") ### This is required so that R uses the libraries loaded in the image and not any local libraries
library(Seurat)
library(ggplot2)
library(DoubletFinder)
library(dplyr)
library(tidyr)
library(tidyverse)
## Set up parameters ##
out <- "/path/to/doubletfinder/outdir"
SEURAT_RDSect <- "/path/to/preprocessed/SEURAT_RDSect.rds"
doublet_number <- 3200
## make sure the directory exists ###
dir.create(out, recursive = TRUE)
## Add max future globals size for large pools
options(future.globals.maxSize=(850*1024^2))
### Read in the data
seurat <- readRDS(SEURAT_RDSect)
## pK Identification (no ground-truth) ---------------------------------------------------------------------------------------
sweep.res.list <- paramSweep_v3(seurat, PCs = 1:10, sct = TRUE)
sweep.stats <- summarizeSweep(sweep.res.list, GT = FALSE)
bcmvn <- find.pK(sweep.stats)
plot <- ggplot(bcmvn, aes(pK, BCmetric)) +
geom_point()
ggsave(plot, filename = paste0(out,"/pKvBCmetric.png"))
## Homotypic Doublet Proportion Estimate -------------------------------------------------------------------------------------
annotations <- Idents(seurat)
homotypic.prop <- modelHomotypic(annotations)
nExp_poi <- doublet_number
print(paste0("Expected number of doublets: ", doublet_number))
nExp_poi.adj <- round(doublet_number*(1-homotypic.prop))
## Run DoubletFinder with varying classification stringencies ----------------------------------------------------------------
seurat <- doubletFinder_v3(seurat, PCs = 1:10, pN = 0.25, pK = as.numeric(as.character(bcmvn$pK[which(bcmvn$BCmetric == max(bcmvn$BCmetric))])), nExp = nExp_poi.adj, reuse.pANN = FALSE, sct = TRUE)
doublets <- as.data.frame(cbind(colnames(seurat), seurat@meta.data[,grepl(paste0("pANN_0.25_",as.numeric(as.character(bcmvn$pK[which(bcmvn$BCmetric == max(bcmvn$BCmetric))]))), colnames(seurat@meta.data))], seurat@meta.data[,grepl(paste0("DF.classifications_0.25_",as.numeric(as.character(bcmvn$pK[which(bcmvn$BCmetric == max(bcmvn$BCmetric))]))), colnames(seurat@meta.data))]))
colnames(doublets) <- c("Barcode","DoubletFinder_score","DoubletFinder_DropletType")
doublets$DoubletFinder_DropletType <- gsub("Singlet","singlet",doublets$DoubletFinder_DropletType) %>% gsub("Doublet","doublet",.)
write_delim(doublets, file = paste0(out,"/DoubletFinder_doublets_singlets.tsv"), delim = "\t")
### Calculate number of doublets and singlets ###
summary <- as.data.frame(table(doublets$DoubletFinder_DropletType))
colnames(summary) <- c("Classification", "Droplet N")
write_delim(summary, paste0(out,"/DoubletFinder_doublet_summary.tsv"), "\t")
DoubletFinder Results and Interpretation
After running the DoubletFinder, you will have multiple files in the $DOUBLETFINDER_OUTDIR:
/path/to/output/DoubletFinder
├── DoubletFinder_doublets_singlets.tsv
├── DoubletFinder_doublet_summary.tsv
└── pKvBCmetric.png
Here’s a more detailed description of the contents of each of those files:
DoubletFinder_doublet_summary.tsvA sumamry of the number of singlets and doublets predicted by DoubletFinder.
Classification
Droplet N
doublet
3014
singlet
16395
To check whether the numbe of doublets identified by DoubletFinder is consistent with the expected doublet rate expected based on the number of droplets that you captured, you can use our Expected Doublet Estimation Calculator.
DoubletFinder_doublets_singlets.tsvThe per-barcode singlet and doublet classification from DoubletFinder.
Barcode
DoubletFinder_score
DoubletFinder_DropletType
AAACCTGAGATAGCAT-1
0.206401766004415
singlet
AAACCTGAGCAGCGTA-1
0.144039735099338
singlet
AAACCTGAGCGATGAC-1
0.191501103752759
singlet
AAACCTGAGCGTAGTG-1
0.212472406181015
singlet
AAACCTGAGGAGTTTA-1
0.242273730684327
singlet
AAACCTGAGGCTCATT-1
0.211368653421634
singlet
AAACCTGAGGGCACTA-1
0.626379690949227
doublet
…
…
…
pKvBCmetric.pngThis is the metric that DoubletFinder uses to call doublets and singlets. Typically the
pKvalue at the maximumBCvalue is the best doublet calling threshold.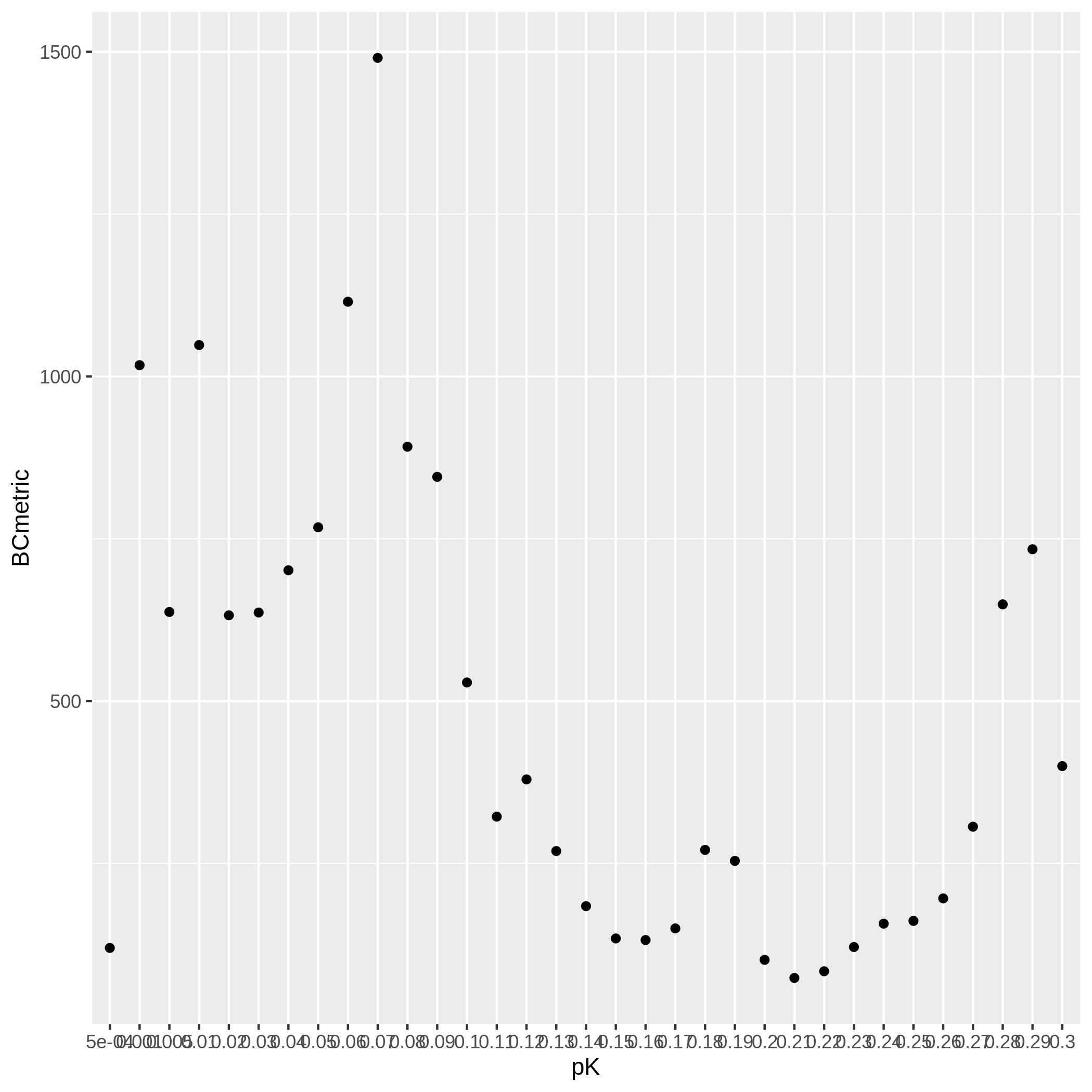
If you do not have a clear
BCmaximum, see responses from the DoubletFinder developer here and here for possible solutions.
Merging Results with Other Software Results
We have provided a script that will help merge and summarize the results from multiple softwares together. See Combine Results.
Citation
If you used the Demuxafy platform for analysis, please reference our publication as well as DoubletFinder.